Efficient storage is the product

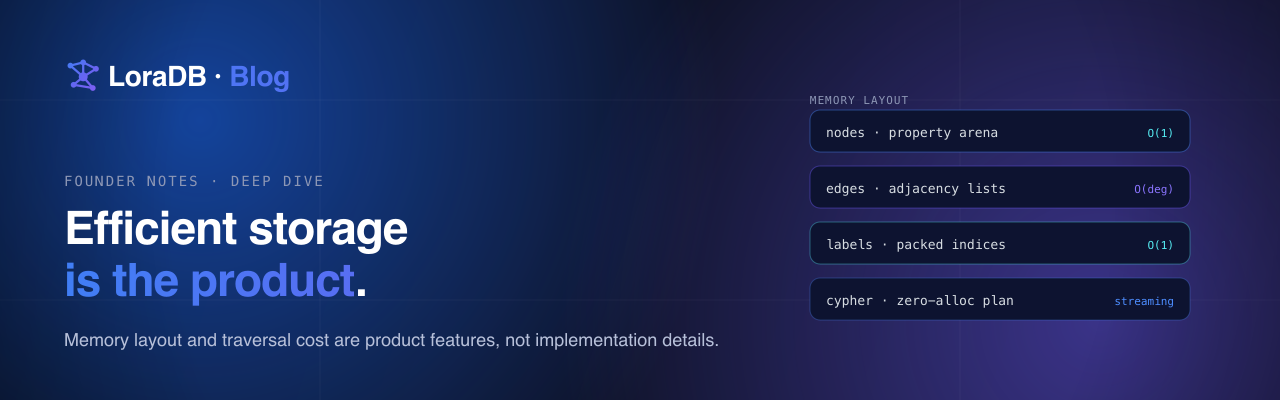
When people talk about graph databases, they usually talk about query languages, visualizations, and relationship modeling. All of that matters. But for the kind of database I wanted, the deeper product question was storage.
If the database is in memory, storage efficiency is not an implementation detail. It is the product boundary.
Every extra allocation is less graph. Every unnecessary clone is less fan-out. Every vague data structure is a future performance mystery. A graph database can have a beautiful query language and still feel wrong if the storage layer wastes the machine.
The Real Cost Of A Graph
Graphs are expensive in a specific way.
A node is not just a row. It has labels, properties, and identity. A relationship is not just a foreign key. It has direction, type, endpoints, and often properties of its own. A traversal needs to find the next relationships quickly, then carry enough state to avoid incorrect paths, cycles, or duplicate rows.
That means the storage layer needs to answer several questions cheaply:
- Which nodes have this label?
- Which relationships leave this node?
- Which relationships enter this node?
- Which relationships have this type?
- What properties are needed for this query?
- Can the executor avoid materializing more than it returns?
If the answer to all of those questions is "scan and allocate," the database may still be simple, but it will not be efficient.
What Bothered Me About Existing Options
This is where my frustration with existing graph databases became concrete.
I liked the graph model. I liked Cypher. I liked being able to express a path in a way that looked like the domain. What I did not like was the cost profile around many systems: too much memory overhead for small graphs, too much operational weight for local workloads, too much indirection when the graph was supposed to be close to the application.
Many graph databases are built for broad, durable, server-side workloads. That comes with real strengths. It also means they carry machinery that a fast embedded or in-process graph engine may not need.
LoraDB starts from a different question:
If the working set is in memory, what is the smallest honest storage model that can support expressive graph queries?
That question shaped the project more than any single feature.
Storage Has To Match The Query Engine
The easiest way to build a database is to keep storage generic and make the executor compensate. The executor can scan, filter, clone, sort, and project until the result is correct.
Correct is not enough.
The storage layer and query engine have to meet in the middle. If a query only
needs n.name, storage should not force the executor to materialize the whole
node. If a pattern expands out from a known node, the executor should be able
to ask for outgoing relationships directly. If a label narrows the candidate
set, the planner should be able to use that fact.
That is why LoraDB is split into small crates. Storage, analyzer, compiler, and executor each have a narrow job, but the boundaries are designed so efficiency can move through the pipeline.
The planner can preserve useful shape. The executor can request the values it needs. The store can provide graph-oriented access paths instead of pretending everything is a table.
Memory Is A Budget, Not A Pool
An in-memory database makes memory visible. That is good.
Disk-first systems can sometimes hide inefficient intermediate structures behind page caches, background work, or larger machines. In-memory systems do not get that luxury. If a query creates too many rows or keeps too many values alive, you feel it quickly.
That pressure leads to better engineering:
- prefer stable identifiers over copying whole entities;
- project only what the query asks for;
- keep intermediate rows narrow;
- make path expansion explicit;
- choose data structures whose cost can be explained;
- avoid turning every operation into a serialization boundary.
The result is not just better performance. It is better developer experience, because the system becomes easier to reason about.
Efficient Storage Changes The Customer Journey
Storage efficiency is not only about serving large users. It helps the first user too.
A developer evaluating LoraDB should be able to start with a laptop and a real slice of data. They should not need to provision an oversized machine because the graph representation is bloated. They should not need to design a caching strategy before writing the first useful query.
Efficient storage makes the journey smoother:
- The local prototype feels fast.
- The first internal workload stays cheap.
- The team trusts that performance comes from the engine, not from accident.
- The hosted platform later has a strong unit economics base.
That last point matters. A hosted database company lives or dies on efficiency. If the core engine wastes memory, the cloud product either becomes expensive or slow. LoraDB's business strategy depends on the same thing the developer experience depends on: doing more with less.
What "Efficient" Means For LoraDB
For LoraDB, efficient storage means:
- graph-native access to nodes and relationships;
- predictable in-memory structures;
- cheap directional traversal;
- clear ownership and borrowing in Rust;
- minimal materialization between query stages;
- APIs that can evolve toward persistence without hiding current costs.
It does not mean the first version is finished. It means the system is built around the right constraint.
I would rather have a smaller database with a storage model I can explain than a larger database that only feels fast in benchmark slides.
The Standard I Want
The standard for LoraDB is simple:
When a developer asks why a query used the memory it used, we should be able to answer.
When a customer asks why hosted LoraDB can be cost-effective, the answer should start in the storage engine, not in pricing tricks.
When a contributor opens the code, the core data structures should be legible.
That is why efficient storage is not a hidden concern. It is the product.
The next post is about trust: how a developer-first graph database becomes a real customer journey instead of just a repository with good intentions.