LoraDB v0.15: benchmarks in public
· 6 min read


LoraDB v0.15 publishes the numbers.
For most of the release journey the only benchmarks people saw were our internal smoke gates: a fixed set of workloads, a baseline, and "don't regress." That's enough to keep the engine honest with itself. It says nothing about how LoraDB compares to the other embedded and server graph engines a reader might already be using.
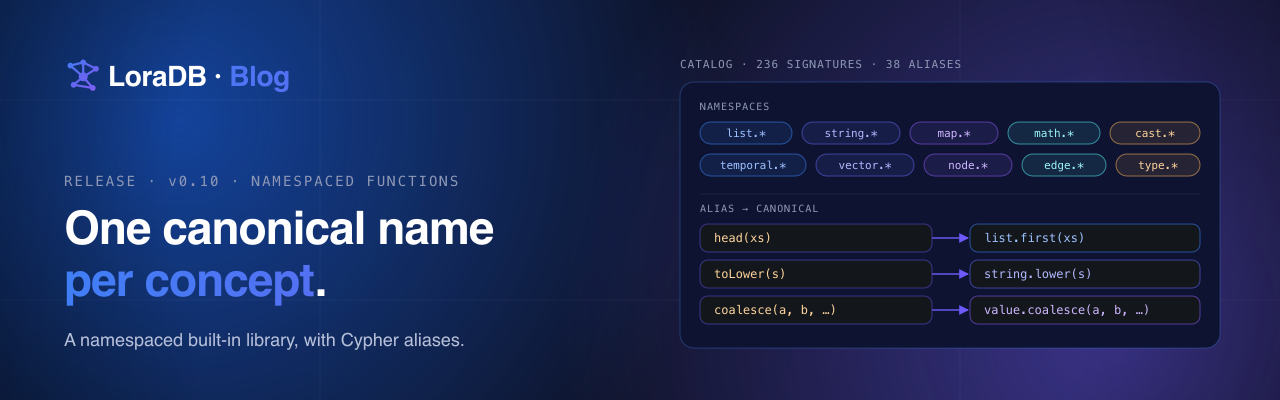
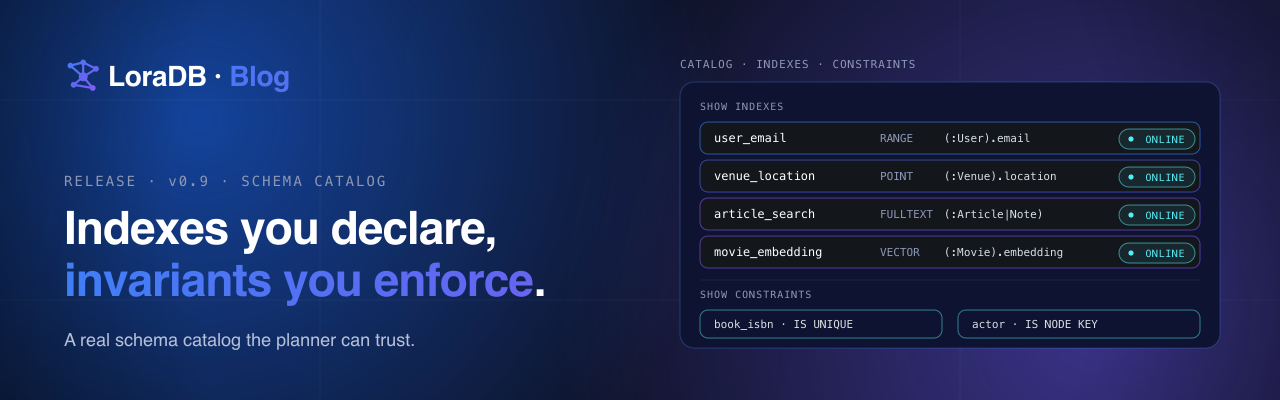
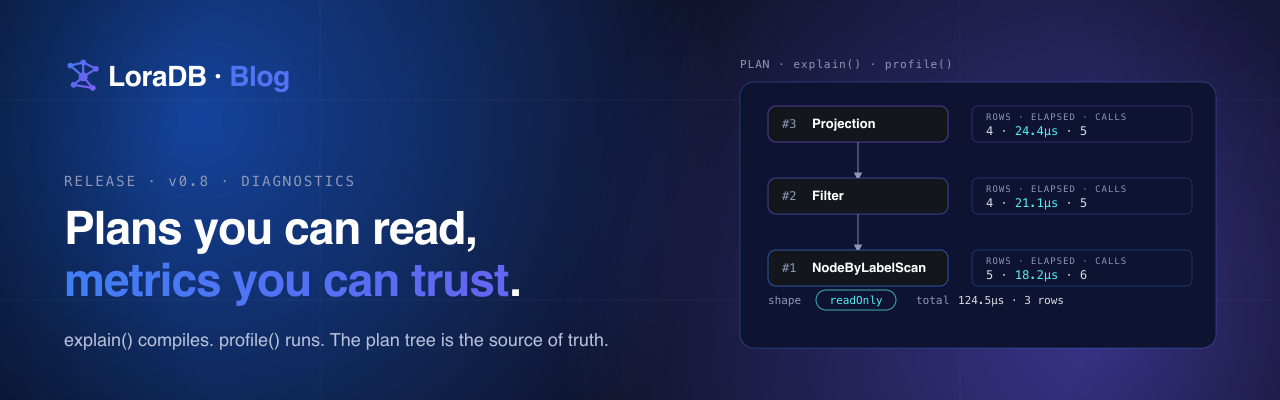
v0.15 closes that gap. The comparisons/ crate that drives the
head-to-head suite is now in tree. The full report is committed at
comparisons/report.md. A new /benchmarks page
renders that report with per-engine ranking, per-group breakdowns,
and a head-to-head page per competitor. Every workload that was
skipped on a given engine carries the reason next to it.