LoraDB v0.4.0: WAL, checkpoints, and crash recovery

LoraDB v0.4.0 adds a write-ahead log.
This release note has been updated with the current binding names. The
v0.4.0 release introduced WAL-backed persistence; current builds also
expose explicit raw-WAL helpers (openWalDatabase, open_wal,
OpenWal) and managed commit-count snapshots on the filesystem-backed
bindings.
The engine is still in-memory and local-first. What changes in this release is the durability boundary: on the surfaces that own a filesystem and process lifecycle, committed writes no longer have to live entirely in RAM between two manual snapshots.
The shortest mental model:
createDatabase()in Node is still a fresh in-memory graph.createDatabase("application", { databaseDir: "./data" })opens a persistent container-backed graph at./data/application.loradb.Database.create("app", {"database_dir": "./data"}),lora.New("app", lora.Options{DatabaseDir: "./data"}), andLoraRuby::Database.create("app", {"database_dir": "./data"})do the same thing on Python, Go, and Ruby.openWalDatabase({ walDir: "./data/wal" }),Database.open_wal("./data/wal"),lora.OpenWal(...), andLoraRuby::Database.open_wal("./data/wal")open explicit WAL directories; pair them with snapshot directories for managed commit-count checkpoints.lora-server --wal-dir /var/lib/lora/walturns the HTTP server into a WAL-backed process.- Rust gets the full open, recover, checkpoint, and sync-mode surface.
Snapshots do not go away. They stay the portable file you can back up, ship, and restore elsewhere. v0.4.0 makes them stronger by giving them something to checkpoint against.
What ships in v0.4.0
| Surface | New durability surface |
|---|---|
Rust (lora-database) | Database::open_with_wal(...), Database::recover(...), Database::checkpoint_to(...), WalConfig, SyncMode |
Node (@loradb/lora-node) | await createDatabase(name, { databaseDir }) for .loradb archives, or await openWalDatabase({ walDir, snapshotDir }) for explicit WAL directories with managed snapshots and sync-mode control |
Python (lora_python) | Database.create(name, {"database_dir": dir}) / AsyncDatabase.create(...) for .loradb archives, or Database.open_wal(wal_dir, options) / AsyncDatabase.open_wal(...) for explicit WAL directories with managed snapshots |
Go (lora-go) | lora.New(name, lora.Options{DatabaseDir: dir}) for .loradb archives, or lora.OpenWal(lora.WalOptions{...}) for explicit WAL directories with managed snapshots |
Ruby (lora-ruby) | LoraRuby::Database.create(name, { database_dir: dir }) for .loradb archives, or LoraRuby::Database.open_wal(wal_dir, options) for explicit WAL directories with managed snapshots |
HTTP server (lora-server) | --wal-dir, --wal-sync-mode, --restore-from, POST /admin/checkpoint, POST /admin/wal/status, POST /admin/wal/truncate |
| Every binding | Snapshot save / load stays available exactly as before |
That split is intentional. Rust and lora-server expose the full
operator surface. Embedded bindings offer two ergonomic shapes: pass a
database name plus a directory for a portable .loradb archive, or use
the explicit WAL helper when you want to manage the WAL and checkpoint
directories yourself. Omit persistence options when you want a fresh
in-memory graph.
The Node shape is deliberately explicit
The Node API is meant to read like the difference between scratch, container-backed, and explicit-WAL storage:
import { createDatabase, openWalDatabase } from '@loradb/lora-node';
const scratch = await createDatabase(); // in-memory
const db = await createDatabase("application", {
databaseDir: "./data",
}); // ./data/application.loradb
const walDb = await openWalDatabase({
walDir: "./data/application.wal",
snapshotDir: "./data/application.snapshots",
snapshotEveryCommits: 1000,
syncMode: "groupSync",
});
await db.execute("CREATE (:Person {name: 'Ada'})");
Reopen the same directory later:
import { createDatabase } from '@loradb/lora-node';
const db = await createDatabase("application", { databaseDir: "./data" });
const { rows } = await db.execute(
"MATCH (p:Person) RETURN p.name AS name",
);
The name is resolved inside databaseDir as a .loradb archive. Relative
paths resolve from the current working directory. Archive-backed named
databases default to grouped fsync with a 1s interval. Raw WAL helpers
default to:
SyncMode::GroupSync8 MiBtarget segment size
Node exposes syncMode for container-backed and explicit WAL opens. It
does not expose WAL status or truncate helpers yet. If you need
that operator surface today, use Rust directly or run lora-server.
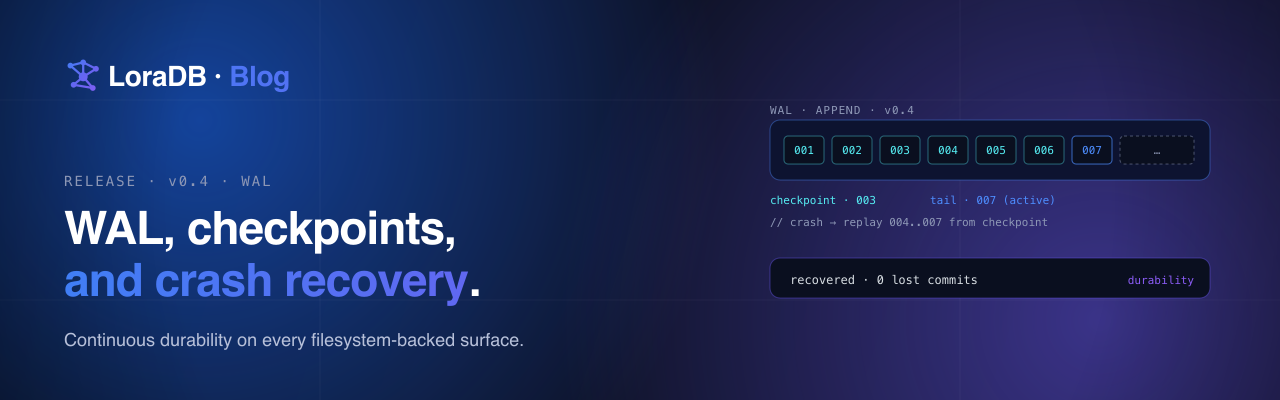
What the WAL actually guarantees
This is not "marketing durability." The contract is concrete:
- Every mutating query is logged before the call returns.
- Read-only queries write nothing to the WAL.
- Recovery replays only committed writes, in commit order.
- A torn tail on the active segment is truncated back to the last valid record.
- A checkpoint writes a snapshot stamped with
walLsn, appends a checkpoint marker, and truncates safe WAL history up to that fence.
That means the engine now has a clean recovery staircase:
- pure in-memory,
- snapshot-only,
- WAL-only,
- snapshot + WAL checkpointing.
The important part is that each step is readable. The release does not blur "we can save a file" together with "we can recover committed writes." Those are different guarantees, and the docs now say so.
lora-server grows into an operator surface
The HTTP server picks up the real production-adjacent durability knobs:
# Fresh boot with a WAL.
lora-server --wal-dir /var/lib/lora/wal
# Snapshot + WAL recovery.
lora-server \
--wal-dir /var/lib/lora/wal \
--snapshot-path /var/lib/lora/graph.bin \
--restore-from /var/lib/lora/graph.bin
And the admin routes that make the log inspectable and manageable:
POST /admin/wal/statusPOST /admin/wal/truncatePOST /admin/checkpoint
WAL durability now uses GroupSync:
| Mode | Meaning |
|---|---|
group-sync | write commits immediately and fsync in the background or on explicit sync/checkpoint/drop |
The server is still honest about its boundary: one process, one graph, no auth, no TLS, no multi-database routing. The durability story is stronger, but it is still a small local system, not a hosted graph service in disguise.
What did not change
v0.4.0 is a durability release, not a reinvention of the product:
- LoraDB is still an in-memory engine.
- Snapshots are still manual and explicit.
- There is still no wall-clock checkpoint scheduler. Raw-WAL helpers can write managed snapshots after N committed transactions.
- Full checkpoint, truncate, and status controls still live on Rust and
lora-server; Node exposes sync-mode control, while Python, Go, and Ruby keep the raw-WAL helper intentionally small. - WASM stays snapshot-only and pathless, using
saveSnapshot/loadSnapshot. - The HTTP admin surface is still unauthenticated and meant to live behind your own ingress.
That last point matters. The new admin routes are useful, but only when deployed behind a boundary you control.
The docs changed with the product
This release also forced a documentation cleanup across the website. The main fixes:
- the embedded-binding docs now state the initialization rule
explicitly: no argument means in-memory, name plus directory means
.loradbcontainer-backed, and explicit WAL helpers own raw WAL directories; - the HTTP server and API docs no longer describe a pre-WAL world;
- snapshots are now documented as a standalone primitive that can also act as a checkpoint target;
- there is a dedicated WAL page instead of scattering durability details across unrelated guides.
The result is that the website now answers the operational questions in the same place the release introduces them.
Read next
v0.3 made "save the graph to one file" real. v0.4.0 makes "reopen the process and keep committed writes" real. That is the release.