In-memory or it does not work

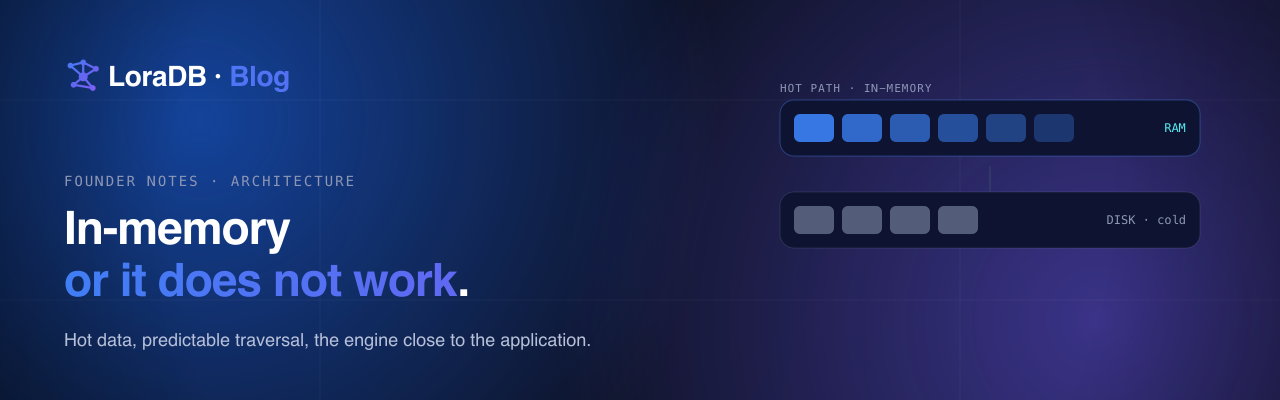
The phrase "in-memory database" can sound like a performance trick. For LoraDB, it is more basic than that. The product I wanted to build did not make sense if the graph was slow to touch.
Graphs are not like simple key-value lookups. The interesting queries walk. They expand. They branch. They filter while moving through relationships. A single product interaction can turn into a set of small traversals that need to feel instant.
If the graph is on the hot path, latency is not an optimization. It is the product.
The Moment A Graph Becomes Product Logic
The first version of a graph workload is often a background report:
MATCH (a)-[:CONNECTED_TO*1..3]->(b)
RETURN a, b
LIMIT 100That can be slow and still useful. Someone waits, gets an answer, and learns something.
But the workloads I cared about moved closer to the user:
- Which related entities should appear while someone is typing?
- Which memories should an agent read before choosing a tool?
- Which product, document, or event is connected enough to matter now?
- Which path explains why two things are related?
Those are not nightly jobs. Those are interaction-time questions.
Once a graph query becomes product logic, a few milliseconds change the shape of what you can build. You stop treating the graph as a separate analytics system and start treating it as part of the application runtime.
That is where in-memory starts to matter.
Why A Remote Database Often Felt Wrong
Remote databases are powerful. They centralize state. They add durability, access control, replication, backup, and operational boundaries.
They also add distance.
For a graph workload, that distance can be painful because the query engine is already doing pointer-heavy work. Relationship expansion is not one lookup; it is a sequence of dependent reads. If the system has to cross process, network, serialization, and storage boundaries for every meaningful step, the database may still be correct, but the product no longer feels direct.
With LoraDB, I wanted the first experience to be different:
- the graph lives next to the code;
- the query engine runs in the same machine;
- the storage layout is optimized for traversal;
- the cost of experimenting is low;
- tests can spin up a database without infrastructure.
That is not the only valid architecture. It is the right first architecture for the customer journey I wanted.
Fast Is Not Just Benchmarks
I care about benchmarks, but benchmarks are not the whole story.
For a developer trying a database, "fast" means:
- the server starts quickly;
- small graphs load quickly;
- common queries complete without surprise;
- the API does not force unnecessary data conversion;
- the result shape is predictable;
- the failure mode is understandable.
A graph database can post impressive numbers and still feel slow if every interaction requires operational setup. It can also feel unreliable if a query allocates aggressively, materializes too much, or hides planner choices.
LoraDB's first design goal was to make the happy path cheap:
MATCH (u:User)-[:LIKES]->(topic:Topic)
WHERE u.id = $user_id
RETURN topic.name
ORDER BY topic.score DESC
LIMIT 10That kind of query should not feel like an analytics job. It should feel like ordinary application code.
Why Cypher Still Matters
If speed were the only goal, the easiest answer would be a custom Rust API with hand-written traversal functions. That would be faster to implement and easier to optimize in the narrow case.
But it would make the customer journey worse.
Cypher gives the database a shared language. A developer can look at a query and understand the shape of the graph. A teammate can review it. A user moving from another graph system does not have to learn an entirely new model before getting value.
The tradeoff is implementation cost. A real query language means parser, semantic analysis, planning, execution, projection, aggregation, paths, functions, errors, and documentation.
I accepted that cost because the goal was not just "fast graph operations." The goal was a database.
Why In-Memory Does Not Mean Toy
There is a common assumption that in-memory means temporary, toy, or non-serious. I think that assumption comes from confusing deployment model with engineering quality.
An in-memory graph database can still have:
- a real query language;
- a real planner;
- typed values;
- path semantics;
- deterministic tests;
- production use for internal workloads;
- clear boundaries for future persistence.
Starting in memory makes the first version more honest. It forces the core engine to be useful before the system grows persistence, clustering, and managed operations around it.
For LoraDB, that was important. I did not want to hide inefficiency behind hardware. I wanted the engine to be small enough that performance problems had nowhere to hide.
The Product Feeling
The product feeling I wanted is this:
You clone the repo. You run the server. You send a Cypher query. You get a result. You can read the code path from HTTP request to query plan to graph storage without losing the thread.
That feeling builds trust.
Trust is what turns a curious developer into an adopter. Adoption is what makes a hosted platform possible later. The hosted product can add persistence, backups, scaling, dashboards, auth, and operational guarantees, but the core has to feel right first.
That is why LoraDB begins in memory.
The next post is about the second constraint: storage efficiency. Because a fast in-memory graph database is only useful if it uses memory carefully.