LoraDB v0.10: one canonical name per concept

LoraDB v0.10 is a function-surface release.
v0.5 made the engine stream. v0.6 made persistence feel like a system. v0.7 was a process release. v0.8 made the planner and executor observable. v0.9 gave the planner a real schema catalog.
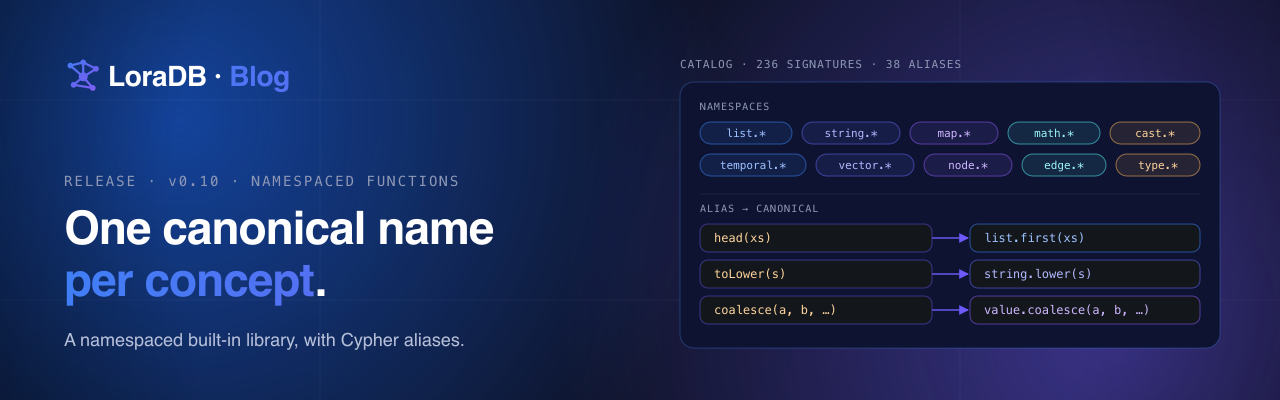
v0.10 does the same thing for the function library: the engine now has one canonical name per concept, grouped into namespaces, with the analyzer, executor, optimizer, docs, and binding tests all reading from the same table.
The shape of the change
LoraDB used to ship a flat soup of function names: head, tolower,
substring, coalesce, vector.similarity.cosine, randomUUID,
toIntegerOrNull, keys, id, type. Some were single-word, some
were dotted, some came from Cypher, some from convenience.
That worked while there were sixty of them. With v0.10 there are 236, covering text, numbers, lists, maps, temporal values, bytes, bits, geo, vectors, graph entities, paths, type inspection, and explicit casts.
The fix is structural, not cosmetic. Every built-in now lives at
<namespace>.<operation>, both segments snake_case:
RETURN string.upper('hello') AS greeting,
list.first([1, 2, 3]) AS head,
math.clamp($x, 0, 100) AS bounded,
temporal.between(date('2024-01-01'), date()) AS age,
value.coalesce($preferred, $fallback, 'n/a') AS pick,
cast.try($maybe_int, INTEGER) AS as_int;The rules are enforced module-wide, not per function:
- Two segments only —
namespace.operation. snake_casefor both segments.- Namespaces name the value family or concern (
list.*,string.*,vector.*,node.*). Runtime type questions live undertype.*; conversions live undercast.*. - One operation per concept. Behaviour varies by arguments, not by
suffix — no
sortMaps/sortNodes/sortText, justlist.sort. - Predicates return
BOOLand read as a question (is_,has_,contains,equal_unordered,all_distinct). - Pure functions only. Mutating procedures live in the procedure dispatcher, not in the function library.
Sixteen namespaces
The full catalog groups into sixteen pure namespaces and four storage-aware namespaces.
| Namespace | What lives there |
|---|---|
list.* | Set-like ops, indexing, reshaping, windowing, sampling. |
string.* | Case, search, slicing, padding, encoding, regex. |
text.* | Fuzzy distance, similarity, phonetic match. |
map.* | Map lookup, patching, nested paths, entries, group/index by. |
number.* | Formatting, radix conversion, numeric predicates. |
bits.* | Integer bit operations. |
math.* | Numeric formulas, rounding, trig, constants, random. |
temporal.* | Now/today/timestamp, parse/format, get/truncate, between. |
bytes.* | Length, encode/decode, compress/decompress. |
crypto.* | blake3, crc32. |
uuid.* | new, from_string, is_valid. |
json.* | Encode, decode, path lookup. |
geo.* | Point distance and bbox predicates. |
vector.* | Dimension and similarity helpers. |
type.* | type.of(x), type.is(x, TYPE) — runtime type questions. |
cast.* | cast.to, cast.try, cast.can — explicit conversion. |
node.* | node.id, node.labels, node.has_label, node.keys, node.properties. |
edge.* | edge.id, edge.type, edge.start, edge.end, edge.keys, edge.properties. |
path.* | path.nodes, path.edges, path.length, path.first, path.last. |
value.* | Polymorphic helpers that apply across families: value.size, value.coalesce, value.is_null, value.id. |
That gives every developer a search shape: when you don't remember the exact name, you remember the namespace and tab through it.
A single source of truth
The catalog lives in one file, owned by the analyzer:
// crates/lora-analyzer/src/analyzer/builtin_signatures.rs
pub const BUILTIN_SPECS: &[BuiltinSpec] = &[
spec("list.first", 1, Some(1)),
spec("list.sort", 1, Some(2)),
spec("string.upper", 1, Some(1)),
spec("string.slice", 2, Some(3)),
spec("math.clamp", 3, Some(3)),
spec("temporal.between", 2, Some(2)),
spec("vector.similarity", 2, Some(3)),
spec_type("cast.try", 2, Some(2), &[1]),
// …236 entries total
];
Every entry carries an arity range and, where it matters, the argument
slots that accept type literals (DATE, INTEGER, VECTOR<FLOAT32>(384))
or enum-like literals (COSINE, EUCLIDEAN).
The executor never re-declares names. It exposes a dispatch arm per
namespace, and a small drift-safety test in the executor walks
BUILTIN_SPECS and asserts that every entry resolves to an
implementation:
#[test]
fn every_signature_has_a_dispatch_arm() { /* … */ }
#[test]
fn every_signature_is_two_segments_and_snake_case() { /* … */ }
If you add a row to the table without an executor arm, the test fails. If you add a non-snake-case name, the test fails. If you add a dispatch arm without a signature, the analyzer rejects calls before they reach you. Drift between the surface and the runtime is no longer possible.
Aliases — for the names you already type
The new tree would be a worse experience if every existing query had to be rewritten. v0.10 keeps every familiar Cypher spelling working through analyzer aliases:
| You write | Resolves to |
|---|---|
head(xs), last(xs) | list.first(xs), list.last(xs) |
coalesce(a, b, …) | value.coalesce(a, b, …) |
toLower(s), toUpper(s) | string.lower(s), string.upper(s) |
left(s, n), right(s, n), substring(s, …) | string.prefix, string.suffix, string.slice |
reverse(x), size(x), keys(x), properties(x) | value.reverse, value.size, value.keys, value.properties |
length(p) | path.length(p) |
id(x), labels(n), type(r) | value.id(x), node.labels(n), edge.type(r) |
now(), timestamp(), timezone() | temporal.now, temporal.timestamp, temporal.timezone |
random(), randomUUID() | math.random, uuid.new |
toInteger(x) / toString(x) / toFloat(x) / toBoolean(x) | cast.to(x, INTEGER | STRING | FLOAT | BOOLEAN) |
toIntegerOrNull / toStringOrNull / toFloatOrNull / toBooleanOrNull | cast.try(x, TYPE) |
A second alias family covers in-house migrations from earlier LoraDB spellings:
| Migration alias | Canonical |
|---|---|
list.find_index, list.find_indexes | list.index_of, list.indexes_of |
vector.dim | vector.dimension |
value.first_non_null | value.coalesce |
type.cast, type.try_cast, type.can_cast | cast.to, cast.try, cast.can |
Aliases resolve during analyzer lowering. They never reach the executor. That means no per-binding plumbing, no aliasing-induced ambiguity in plans, and one place to look when you wonder why a name exists.
Why this is the right shape now
Three forces pushed v0.10 to land before any larger function surface work:
Predictability. With sixteen namespaces a developer can guess a name without grepping. The right names for "give me the first list element" or "lowercase this string" or "tell me whether this map has a key" are reachable from the namespace alone.
Drift safety. The analyzer signature catalog and executor dispatch used to be two parallel sources of truth. They drifted. Tests caught some of that; not all of it. The drift-safety tests in v0.10 make the two sources structurally identical — adding a function means adding one line of signature plus one match arm, and the test suite enforces the pairing.
Cross-binding consistency. The bindings (@loradb/lora-node,
@loradb/lora-wasm, lora-python, lora-ruby, lora-go, the
lora-ffi C ABI) call Cypher through the same parser. When the parser
exposes one canonical name per concept, every binding inherits the same
surface for free. The binding tests in v0.10 exercise the namespaced
names directly so a regression in one shows up in all five test
suites.
Pipeline updates
Behind the surface, every layer learned about namespaces:
- Parser —
function_invocationnow acceptsnamespace.operationinvocations and parses the full canonical form. The grammar uses a smallnamespace = (symbolic_name ~ dot)+rule reused for procedure calls. - Analyzer —
BUILTIN_SPECSandBUILTIN_ALIASESresolve every function reference. Aliases are normalized to the canonical spelling before type checking, so the resolved tree always reads canonically. - Compiler —
plan_namespaced_callcovers the new arms in one place; the optimizer can recognize storage-aware namespaces (node.*,edge.*,path.*,value.*) and lower them where beneficial. - Executor — the function library was reorganised into one module
per namespace, with a small dispatcher that returns
Nonefor any name outside the namespace tree. - Database / store / server — internal call sites now use the canonical names. The on-disk format and snapshot codec are unchanged; only the function names in code paths moved.
Examples
Some queries the new shape makes pleasant to write.
A search ranking that combines vector similarity and structure
MATCH (d:Doc)
WITH d, vector.similarity(d.embedding, $query) AS score
WHERE score > 0.6
MATCH (d)-[:MENTIONS]->(e:Entity)
RETURN d.id,
string.upper(d.title) AS title,
value.coalesce(d.summary, '(none)') AS summary,
score,
list.unique(collect(e.name)) AS entities
ORDER BY score DESC
LIMIT 5;Working a list down to a single shape
RETURN list.first(value.coalesce($items, [])) AS head,
list.last($items) AS tail,
list.unique(list.flatten($items)) AS uniq,
list.zip($items, list.range(1, list.size($items))) AS indexed;Parsing and normalising user input
WITH cast.try($input, INTEGER) AS as_int,
string.trim(cast.to($input, STRING)) AS as_string
RETURN value.coalesce(as_int, 0) AS count,
string.lower(as_string) AS key,
type.of($input) AS reported_type,
type.is($input, INTEGER) AS was_int;Temporal arithmetic without remembering the constant names
WITH temporal.now() AS now, $birthday AS dob
RETURN temporal.between(dob, now) AS lived,
temporal.in_days(dob, now) AS days_lived,
temporal.truncate(now, 'day') AS today,
temporal.add(now, duration('P1Y')) AS next_year;Binding behaviour
The bindings did not change shape — db.execute(query, params) returns
the same tagged values it did in v0.9, and the vector / temporal /
spatial helpers still produce the same wire format. What changed is
that every binding's parameter and similarity test now exercises the
namespaced builtin path through Cypher, including via type-cast
literals ([1.0, 0.0, 0.0]::VECTOR<FLOAT32>(3)).
If a binding test exercised vector.similarity.cosine(...) before, it
now exercises vector.similarity(...). Behavioural parity is checked
in the same place as before.
Existing user code keeps working through the alias table.
Documentation
Every namespace has its own reference page; the function overview was
rewritten around the canonical names. A new developer-facing page,
docs/developer/functions.md, documents the rules for adding new
built-ins: signature, executor module, integration test in
builtin_namespaces.rs, docs entry, drift-safety check. The
contribution surface is one page now, not five.
Breaking changes and migration
There are no on-disk migrations. The WAL and snapshot codecs are unchanged.
For Cypher callers, the canonical names are new, but the old spellings
keep working through aliases — including the cases the analyzer used to
special-case (coalesce is variadic, vector.similarity accepts
either two or three arguments, cast.to accepts a type literal in arg
position 1).
For Rust callers, the executor function library was reorganised into
modules per namespace. If you were calling individual builtin
implementations from outside the engine — generally not a supported
path — the module paths changed. If you were calling them through
Compiler::compile + Executor::run, nothing changed.
Notable fixes
- The analyzer now reports a single, consistent error for unknown function names — including a "did you mean" hint when the name matches a namespace prefix.
value.coalesce(...)short-circuits on the first non-null argument even when later arguments would have errored.- Numeric predicates (
number.is_finite,number.is_nan,number.is_integer) accept bothINTEGERandFLOATand never raise. - Type-literal arguments are validated at parse time, not at runtime,
so
cast.to(x, UNKNOWN_TYPE)fails before the query executes.
How v0.10 fits the journey
v0.5 made the engine stream. v0.6 made persistence feel like a system. v0.7 was a process release. v0.8 made the planner and executor observable. v0.9 gave the planner a real schema catalog.
v0.10 makes the function surface itself a system. The analyzer owns public signatures, the executor owns behavior, the docs read off the same names, and the binding tests pin the cross-language contract. The next time we add a function, we add it once.
Still open
This release does not add new computational power. Every function in the canonical tree was reachable in v0.9 — under a different name. What v0.10 buys is a place to put the next forty functions without making the surface less learnable.
The natural extensions are user-defined functions (UDFs) registered
into the same catalog, a documented procedure surface to mirror what
db.index.fulltext.queryNodes / db.index.vector.queryNodes already
look like, and a SHOW FUNCTIONS introspection that reads the
analyzer signature table directly.
Read next
v0.10 is the release where LoraDB's function library stops being a list of names and starts being a library.