LoraDB v0.14: hot paths and honest errors

LoraDB v0.14 is a hardening release.
v0.11 put the engine behind a URL. v0.12 turned vectors into real indexes. v0.13 made data round-trip. v0.14 goes back to the engine and tightens three things that previous releases let slide: the write path, retained memory on large imports, and what an error actually says when something fails.
What ships
A staged auto-commit write path
Before v0.14, an auto-commit query that mutated and then errored mid-execution would leave the live in-memory graph partially mutated. The WAL aborted the batch so durable recovery stayed consistent, but the running process kept the half-applied state and required a restart from snapshot plus WAL to reach a clean baseline.
v0.14 stages the write. The canonical mutating shape now clones the
current store into a staged graph, runs the query against the staged
copy, and only publishes the staged graph after the WAL commit
succeeds. On failure the staged copy is dropped and the live store
stays at the previous commit. The same shape governs both query
auto-commit and the admin / graph_api mutators, so rollback
semantics and WAL ordering live in exactly one place.
A new regression test in crates/lora-database/tests/wal.rs proves
the property: a query that creates a relationship and then runs into
a constraint guard leaves zero new nodes and zero new relationships,
on both the live handle and the WAL-recovered process.
A live fast lane for simple plans
The staged shape costs an O(N+E) clone every write. That is fine for
admin paths but ruinous for the common CREATE, SET, and
single-node DELETE patterns that dominate workload mix.
v0.14 keeps the live Arc::make_mut hot path for plans that are
provably safe to execute directly against the live graph. The OCC
layer inspects the physical plan: if it consists of node-only
CREATEs, scalar SET writes, or DELETEs of just-created nodes
(in any combination the inspector recognises), the engine routes
through run_live_fast_with_durable_recorder. Everything else,
including MERGE, REMOVE, FOREACH, CALL subqueries, and any
plan with UNION, falls through to the staged path.
The fast lane preserves the previous performance characteristics for
bulk UNWIND $rows AS r CREATE (...) ingest. Plans that fail to
clear the safety check pay the clone but gain proper rollback. The
two shapes coexist behind the same run_with_durable_recorder entry
so call sites do not have to choose.
Batch-validated DELETE
The fast lane covers single-node DELETEs of nodes the same query
just created. To make that safe under partial failure, DELETE now
collects every target across every input row, validates the whole
set against the relationship and existence invariants, and only then
applies the mutation. A failure during validation aborts the query
before a single record is removed. Streaming DELETE lost its
per-row fast path in the process, but the batch model is what makes
CREATE ... DELETE legal on the live graph at all.
Property-key interning and Arc<str> keys
A 5-million-row import with eight columns used to write forty million heap copies of the same handful of column-name strings into property maps. The values themselves were a rounding error next to the keys.
v0.14 makes the Properties bag a BTreeMap<Arc<str>, PropertyValue>
and routes every key insertion through a process-wide intern table.
Realistic workloads have at most a few hundred distinct property
names, so the steady-state intern footprint is negligible. Hot
storage paths read the intern table through a thread-local front
cache; misses take a read lock on the global table, with the write
lock acquired only when a genuinely new key appears.
The win is largest where it matters most. The UNWIND $rows AS r CREATE (...) path goes through the intern table at property-bag
construction time; SET of an existing key reuses the existing
Arc<str> directly and skips the intern table entirely. WAL
property-key decoding routes through the same table so replay
allocates one buffer per distinct key across the whole log.
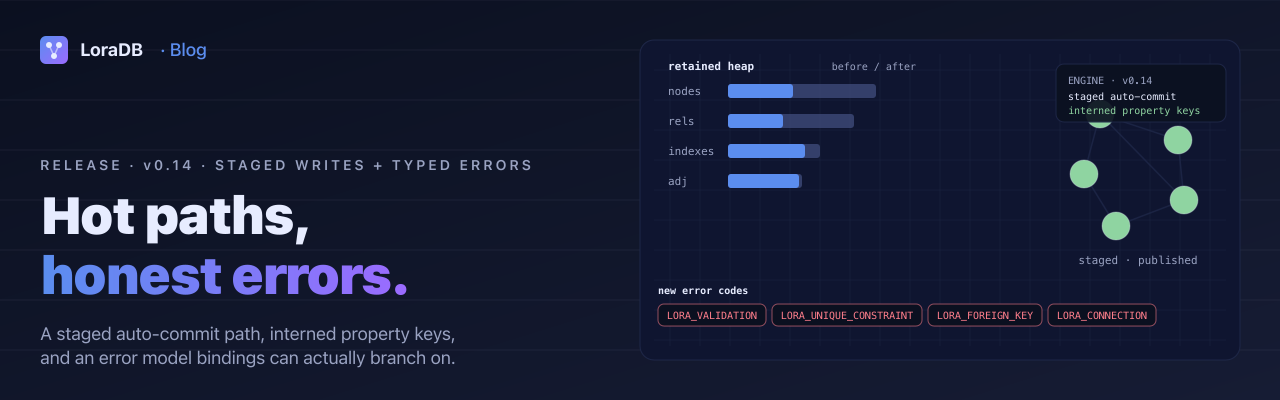
A memory benchmark and a CI gate
A new crates/lora-database/benches/memory.rs bench measures the
retained heap of a representative graph and writes a baseline to
crates/lora-database/benches/memory_baseline.json. A companion
scripts/check-mem-bench.mjs compares the latest bench output
against the baseline with a tolerance band, and a
.github/workflows/memory-bench.yml workflow runs it on every PR
that touches the engine.
A new lora_store::MemoryReport exposes the same retained-heap
breakdown at runtime. The playground's new Stats panel surfaces it.
LoraErrorCode grows up
The engine used to collapse anything that smelled like a constraint
violation into a single LORA_CONSTRAINT code. Bindings could read
the message but not branch reliably on the failure shape.
v0.14 adds six codes that the transport and bindings can pattern-match on:
LORA_VALIDATION, for well-formed requests with semantically invalid values (a vector index with zero dimensions, a procedure parameter with the wrong type).LORA_UNIQUE_CONSTRAINT, for the specific constraint flavour that rejected a duplicate value.LORA_NOT_NULL_CONSTRAINT, for property-existence failures.LORA_FOREIGN_KEY, forDELETEagainst a node that still has relationships and similar cross-record dependencies.LORA_TRANSACTION, for transaction-lifecycle rule violations (committing while a cursor is still active, double-close).LORA_CONNECTION, for anio::Errorof the refused/reset/aborted/not-connected/addr-in-use family, surfaced separately from a genericLORA_IO.
The HTTP transport in lora-server maps the new codes onto standard
HTTP statuses: 422 for LORA_VALIDATION, 409 for the three
constraint-family codes plus LORA_TRANSACTION, 503 for
LORA_CONNECTION and the pre-existing LORA_WAL_POISONED. The
mapping table in docs/design/error-style.md is the canonical
reference.
public_message and debug_context
Server-category errors used to surface their raw text directly to the
HTTP response body. That worked for development but leaked detail
that no production transport should expose: panic messages with
filesystem paths, connection refused strings with internal hosts,
WAL decoding diagnostics. Client-category errors were already safe,
since the messages there name the user's mistake by definition.
v0.14 splits the surface in two. LoraError::message() returns the
original detailed text and stays available to logs and local
debugging. LoraError::public_message() returns a stable, sanitized
sentence for the LoraErrorCategory::Server codes and the original
text for client errors. The HTTP transport now sends public_message
in the response body and logs debug_context() (the full cause
chain) on the server side at tracing::warn or tracing::error
depending on category. A 500 response no longer carries the panic
text that produced it.
JSON rejection routing
The server's admin endpoints used to treat an unparseable JSON body
as either a 400 with no structured body or a panic on the
Option<Json<...>> extractor's surprise behaviours. The admin and
query routes now extract Result<Json<T>, JsonRejection> directly
and feed any rejection through json_rejection_error, which yields a
LORA_INVALID_PARAMS body with the error text the rejection
described. The "no body" case for snapshot save / load / checkpoint /
truncate still works, because MissingJsonContentType is treated as
an absent body rather than an error.
POST /query also gained a params field this release. The body
shape matches /explain and /profile, so a Cypher template can be
sent with bound parameters in one round trip instead of being
re-rendered server-side.
Bindings catch up
Every binding ships the new codes:
lora-node: the TypeScriptLoraErrorCodeunion and the runtimeKNOWN_ERROR_CODESset both include the six additions, and the binding's snapshot-validation tests assert on the precise code.lora-wasm: the worker protocol and the main-thread client expose the same codes, plus aMemoryReportSnapshottype for the new diagnostic surface.lora-ffi,lora-go,lora-python,lora-ruby: code enums extended in sync withLoraErrorCode.crates/bindings/shared-ts: the shared TypeScript type definitions that the wasm and node bindings both consume now include the expanded union as a single source of truth.
The playground catches up too
- A new Inspector edit panel. Open a node or relationship card,
hit Edit, and type into a per-property row. Required keys
(uniqueness, node key, NOT NULL) are marked so you can not
accidentally drop them. Cancel rolls back; Save runs the right
SET/REMOVEmix in one transaction and updates the popup in place. - A new Stats side panel. Per-label and per-rel-type counts. The
active set of secondary indexes. A retained-heap breakdown
attributing memory to nodes, relationships, adjacency lists,
label/type indexes, and each kind of secondary index. The numbers
come from the same
MemoryReportthe CI benchmark uses. - A Confirm-and-remove dialog in the schema browser. Right-click
a label, rel-type, constraint, or index and pick Remove. The
dialog renders the exact Cypher it will run (a
DETACH DELETEfor label nodes, a typedDELETEfor relationships, the canonicalDROP CONSTRAINT/DROP INDEXfor catalog entries) so nothing happens without showing what it does. - Import dialog stale-update guards. Opening a second file while the first is still sniffing no longer races; the dialog tags each preview and review request with a request id and drops responses for superseded requests.
- IndexedDB persistence reject-cache fix. A failed initial open used to poison the cached promise; subsequent calls saw the same rejection forever. Reads now bubble the error instead of swallowing it, and a failed open clears the cache so the next call retries.
And the smaller things
lora-storeexposes aMemoryReportretained-heap breakdown for the in-memory backend and the per-component byte totals it attributes work against.- The WAL no longer panics on LSN or segment-id overflow; both
saturate. The doc strings on
Lsn::nextandSegmentId::nextwere optimistic about the cooperative monotonicity contract; this is belt and braces. - The CSV streaming decoder amortises its drain. Each chunk used to
pay one
memmoveper record; now it pays one per chunk. Imports with millions of small rows feel the difference. lora-snapshotcolumnar decoding routes its array lookups through.get()instead of direct indexing, so a corrupted column offset is a typed decode error rather than a panic.- The WASM build now links with
--max-memory=4294967296so a multi-million-row CSV import does not abort below the browser's practical ceiling. - A handful of builtins (
list.range,list.at,list.slice,math.lcm,datetime("...")) had panic edges on adversarial input; those are nowNullreturns.
What is deferred
A few items from the design plan are not in v0.14 and are tracked as follow-ups:
- The OCC fast-path inspector is conservative. Patterns like
MATCH ... SET n.x = some_function(n.y)still take the staged path; broadening the inspector to cover scalar function applications is the obvious next step. - The memory benchmark is single-shape today (a 100k-node graph with a fixed property mix). Expanding it to cover vector-heavy and text-heavy graphs is the next round of bench infrastructure.
- The
public_messagestrings are intentionally generic. A future release will give each server-category code a slightly more specific recovery hint without leaking provenance.
None of these block the release; they are the next round of work.
Try it
cargo add lora-database
Or open play.loradb.com, drop a CSV onto the page, and watch the Stats panel update as the import lands.
The full changelog and binaries are on the v0.14.0 release page.